In this short post we introduce gitea-ci-autoscaler, a small Rust service we built to provision and tear down CI runner nodes for Gitea Actions on demand.
Let's look at the basic idea behind it and at two Rust patterns that make the implementation pleasant to work with.
Why we built this
We use Gitea Actions for CI across our projects. The problem with self-hosted runners on fixed infrastructure is simple: you either pay for idle servers or wait in queues during bursts. Gitea does not offer built-in autoscaling, so runner registration and infrastructure provisioning are entirely up to you.
So we built something that spins up Hetzner Cloud nodes when CI jobs are waiting and tears them down again when they are not.
How it works
The autoscaler runs inside a K3s cluster and polls every 5 seconds. In each iteration it queries Gitea for waiting jobs and registered runners, Hetzner for provisioned servers, and Kubernetes for nodes and runner pods. It then reconciles all of that into one internal view of the managed nodes.
When jobs are waiting it scales up by creating new Hetzner servers with cloud-init scripts that auto-join the K3s cluster. When nodes sit idle it tears them down in multiple steps:
- deregister the Gitea runner
- drain the Kubernetes node
- delete the Kubernetes node
- delete the Hetzner server
We only tear down servers near the end of their paid billing hour. Hetzner charges per hour, so deleting a server 10 minutes in would waste 50 minutes you already paid for.
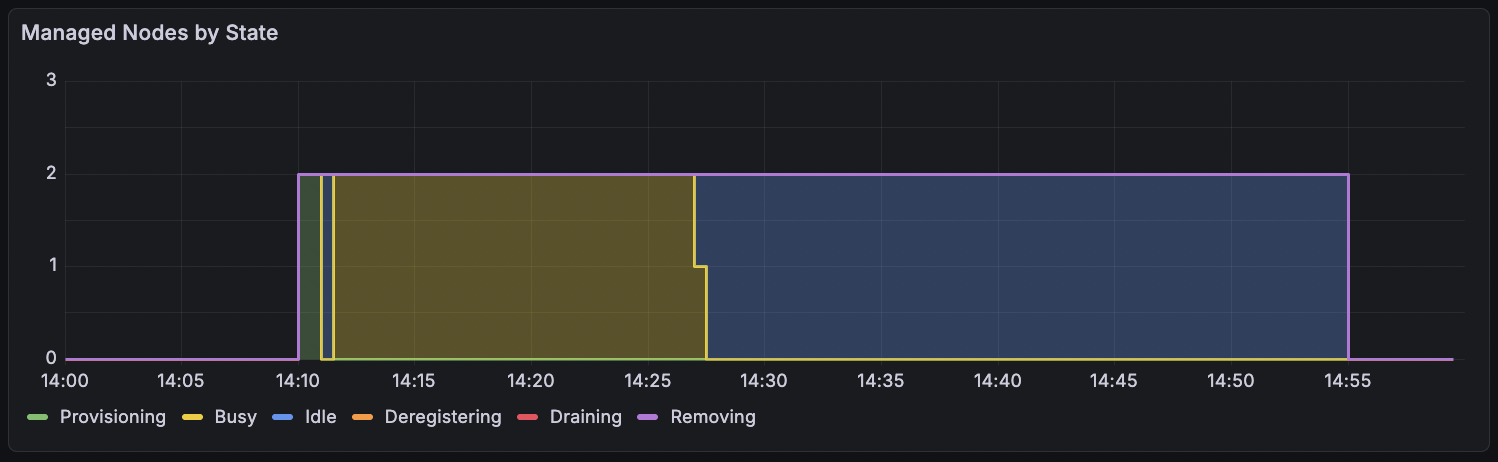
Here is what this looks like in our Grafana dashboard. You can see two nodes being provisioned, doing work, going idle and eventually being torn down:
Modeling the node lifecycle
Each managed node goes through a small but well-defined lifecycle. A Rust enum is a natural fit for this:
pub enum NodeState {
Provisioning,
Busy {
k8s_node_name: String,
gitea_runner_id: u64,
gitea_runner_name: String,
},
Idle {
k8s_node_name: String,
gitea_runner_id: u64,
gitea_runner_name: String,
idle_since: DateTime<Utc>,
},
Deregistering {
k8s_node_name: String,
gitea_runner_id: u64,
},
Draining {
k8s_node_name: String,
},
Removing,
}
Each variant carries exactly the data relevant to that phase. A Provisioning node has no K8s name yet. A Busy node knows its runner. An Idle node tracks when it became idle so we can decide whether it has been sitting long enough to tear down. As teardown progresses each state carries less data because some resources have already been cleaned up.
The nice thing here is that the compiler prevents you from accidentally accessing a runner ID on a node that has already been deregistered. The data simply is not there anymore.
Testing without cloud resources
The autoscaler talks to three external APIs: Gitea, Hetzner and Kubernetes. We obviously do not want tests hitting real infrastructure, so each API client is defined as a trait:
#[async_trait]
pub trait HetznerClient: Send + Sync {
async fn create_server(&self, name: &str, cloud_init: &str)
-> anyhow::Result<HetznerServer>;
async fn list_servers(&self) -> anyhow::Result<Vec<HetznerServer>>;
async fn delete_server(&self, server_id: i64) -> anyhow::Result<()>;
}
GiteaClient and KubeClient follow the same pattern. In production we use HTTP-backed implementations. In tests we swap in mocks that track calls and can simulate failures.
This lets us validate the full teardown lifecycle without spinning up a single server:
#[tokio::test]
async fn teardown_order() {
let mock_gitea = MockGiteaClient::new();
let mock_kube = MockKubeClient::new();
let mock_hetzner = MockHetznerClient::new();
// ... set up an idle node ...
// Step 1: deregister the Gitea runner
mgr.teardown_step(0, &mock_gitea, &mock_kube, &mock_hetzner, &metrics).await;
assert!(matches!(mgr.nodes[0].state, NodeState::Deregistering { .. }));
// Step 2: drain the K8s node
mgr.teardown_step(0, &mock_gitea, &mock_kube, &mock_hetzner, &metrics).await;
assert!(matches!(mgr.nodes[0].state, NodeState::Draining { .. }));
// Step 3: delete K8s node + Hetzner server
mgr.teardown_step(0, &mock_gitea, &mock_kube, &mock_hetzner, &metrics).await;
assert!(mgr.nodes.is_empty());
}
Each call to teardown_step advances the node exactly one state forward. The test verifies the exact ordering of deregister, drain and remove, and the mocks let us assert which API calls were made along the way.
Further steps
The current version is built around our stack: Hetzner and K3s. But the trait-based architecture also lends itself to a few obvious extensions:
- Other cloud providers like AWS or DigitalOcean behind the same trait
- Full Kubernetes support beyond K3s, making it usable in managed clusters like EKS, GKE or AKS
- Ephemeral runners created fresh per job and destroyed after for better isolation
- A Kubernetes controller so it can run in clusters that already have their own node autoscaling and only manage the runner lifecycle on top
The project is MIT licensed and has been running in production for our CI. If you are using Gitea Actions with self-hosted runners and want to stop paying for idle machines, give it a try.